OpenInfer 0.1.0: Writing a Production-Grade Inference Engine in Rust
Code: github.com/openinfer-project/openinfer
Blog:
After the previous article, “Writing a Rust Inference Engine from Scratch”, was published on February 17, 2026, 116 days have passed. Looking back, what benefits did writing an inference engine in Rust actually bring, and what difficulties did it go through? What is Pegainfer’s state now?
When I wrote Pegainfer at that time (this name came from an earlier project of mine called Pegaflow, a KV cache offloading system for vLLM; see the vLLM blog for details) — they are both called pega, from the Greek Pegasus (the Pegasus constellation), which is also the source of the logo: we hope to deliver inference services at a Pegasus-like speed. The starting point was indeed very simple: I like Rust, I also like researching inference technology, I do not like the bloated feeling of the current Python ecosystem, and I had stepped on quite a few Python-related pits in actual production. So the thought of “writing my own inference engine in Rust” appeared. After that, the more I wrote, the more interesting points I found. Whether writing kernels or designing some modules, it satisfied a lot of my curiosity.
At the beginning, it was still something with “deliberate blanks” (at first I only wanted to use it for teaching purposes): it could only handle one request at a time, had no sampler, no prefix cache, no scheduler, no CUDA Graph, and the kernels were not tuned much either. Running Qwen3-4B on a 5070ti was about 70 tokens/s, with accuracy aligned to HuggingFace.
Half a year has passed: sampling, prefix cache, continuous batching scheduler, CUDA Graph, kernel optimization, then linear attention, KV offloading, LoRA, tensor parallelism, and then EP parallelism for mainstream large MoE models. A few days ago I renamed it to OpenInfer, because I found that it could gradually step into production. After proper preparation, today OpenInfer 0.1.0 is officially released.
Of course, most of the features below are only implemented on Qwen3 4B. Different models have different feature coverage.
Architecture: No Longer Making Wheels From 0
Section titled “Architecture: No Longer Making Wheels From 0”Although I want to write an inference engine, that does not mean I need to completely rewrite every part: tokenizer, request parsing, tool call parser, and so on. So I connected many excellent libraries and components from the Rust ecosystem.
Although I quoted Feynman’s sentence “What I cannot create, I do not understand” at the beginning, to me, understanding a system does not mean every line of code has to be typed by me personally. So openinfer uses Rust to glue together several components that I think are well written, stitching them into an inference engine.
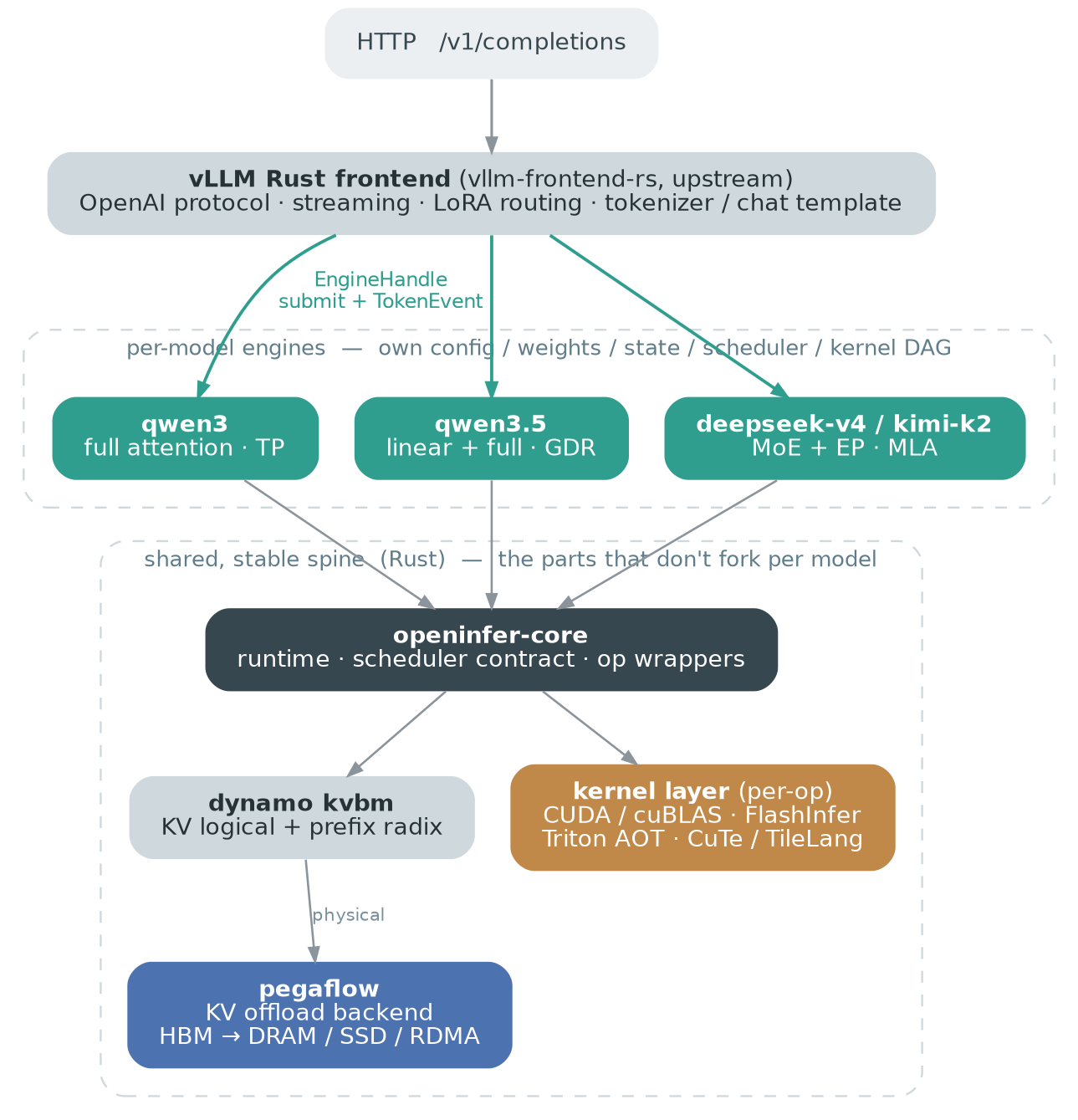
vLLM’s Rust frontend: OpenAI protocol, streaming, LoRA routing. We directly reuse vLLM upstream’s Rust frontend (earliest it was Inferact’s vllm-frontend-rs, later merged into vllm-project/vllm) — tokenizer, chat template, and the protocol layer are already done very well by the vLLM Rust frontend. BTW, openinfer also contributed 3 PRs to the upstream vLLM Rust frontend (from other people in the openinfer community and me).
Dynamo’s kvbm: Dynamo is an ecosystem open-sourced by NVIDIA to provide high-quality inference service under large-scale deployments such as data centers. We connected to its component for managing KV Cache, called kvbm. We connected to its logic layer to manage token prefix cache and eviction (in the future we can also connect to Dynamo’s KV event along the way, providing high-quality distributed routing and P/D disaggregation). We did not connect to its physical layer; for the physical layer I chose pegaflow.
Pegaflow: KV offloading, discussed separately later.
Kernel layer: mainly uses FlashInfer operators, and of course there are also some operators maintained by ourselves (CUDA, Triton, TileLang, CuTe DSL).
The sources of kernels are these:
- GEMM and fused operators on the hot path (QKV, gate-up, attention): handwritten CUDA + cuBLAS.
- Sampling, attention, norm, MLA decode: FlashInfer.
- Qwen3.5’s GDR linear attention: Triton AOT (from the FLA repository).
- DeepSeek-V4’s MoE / compressor / indexer: CuTe DSL + TileLang build-time codegen.
- TVM FFI: wraps the CUBIN compiled by Triton into a directly callable launcher.
Our kernels use feature gates. Each model only compiles the operators it uses. Qwen3 4B does not need to compile the operators of Qwen3.5 4B, nor does it need to compile the TileLang operators for DeepSeek v4 flash, including Kimi’s MoE operators. This can greatly reduce the number of kernels compiled and speed up iteration efficiency.
After modifying one operator, finishing compilation of the whole binary, and running pressure testing again only takes about 50 seconds.
So What Are the Benefits of Choosing Rust?
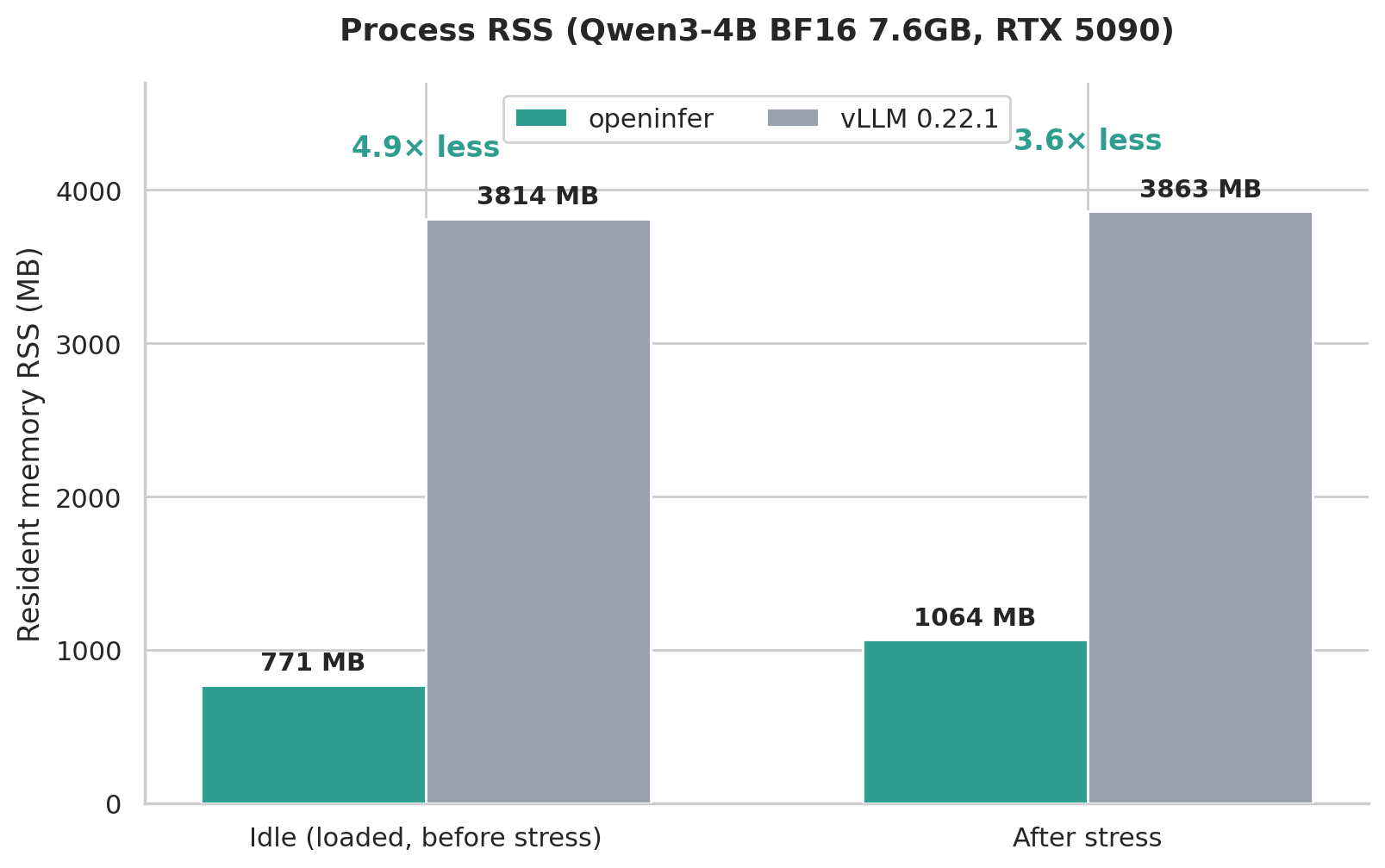
Section titled “So What Are the Benefits of Choosing Rust?”CPU memory usage. Maybe because there is no PyTorch, and no various other components, the process itself is much lighter.
In one round of pressure testing, memory usage was measured before pressure testing started (after the model was loaded and ready while idle) and after pressure testing finished (5090, Qwen3-4B BF16, weights 7.6GB). At the same time, because of the memory safety brought by the Rust language itself, openinfer may have fewer memory problems.
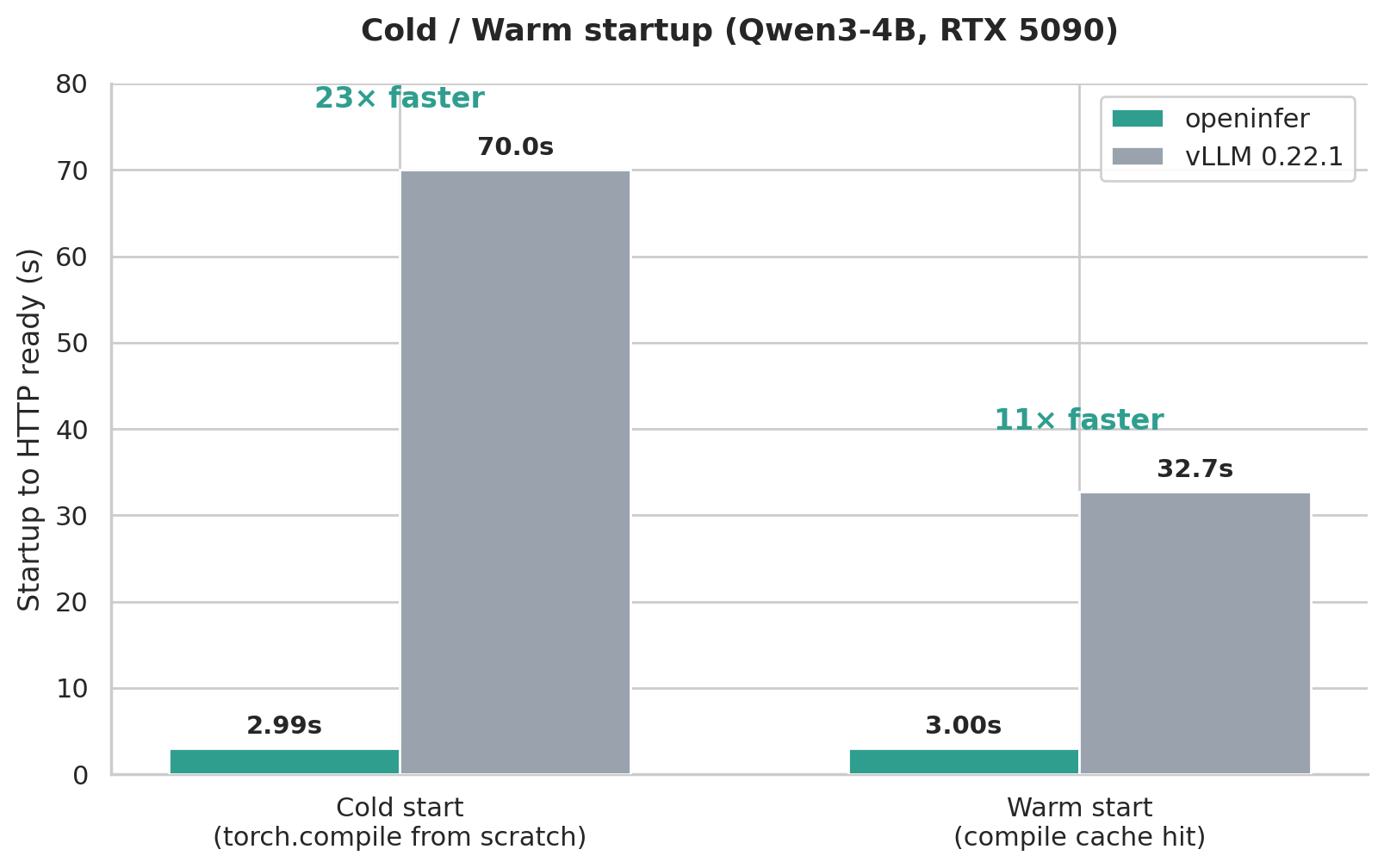
Then, because we do not have all kinds of JIT, compile, and so on, startup speed is very fast. On my PC, with the model pre-warmed, openinfer 3.0s vs vLLM warm start 32.7s, about 11 times (vLLM cold start needs about 70s). In contrast, we do not have any runtime compilation. After it is compiled and the service is ready, what is provided is stable and reliable service.
Actual Measurements of Inference Performance
Section titled “Actual Measurements of Inference Performance”The data was measured on one RTX 5090, using the same vLLM bench serve client, the same Poisson arrivals, and the same seed 42, driving openinfer and vLLM 0.22.1 one after the other. The two engines saw exactly the same request stream.
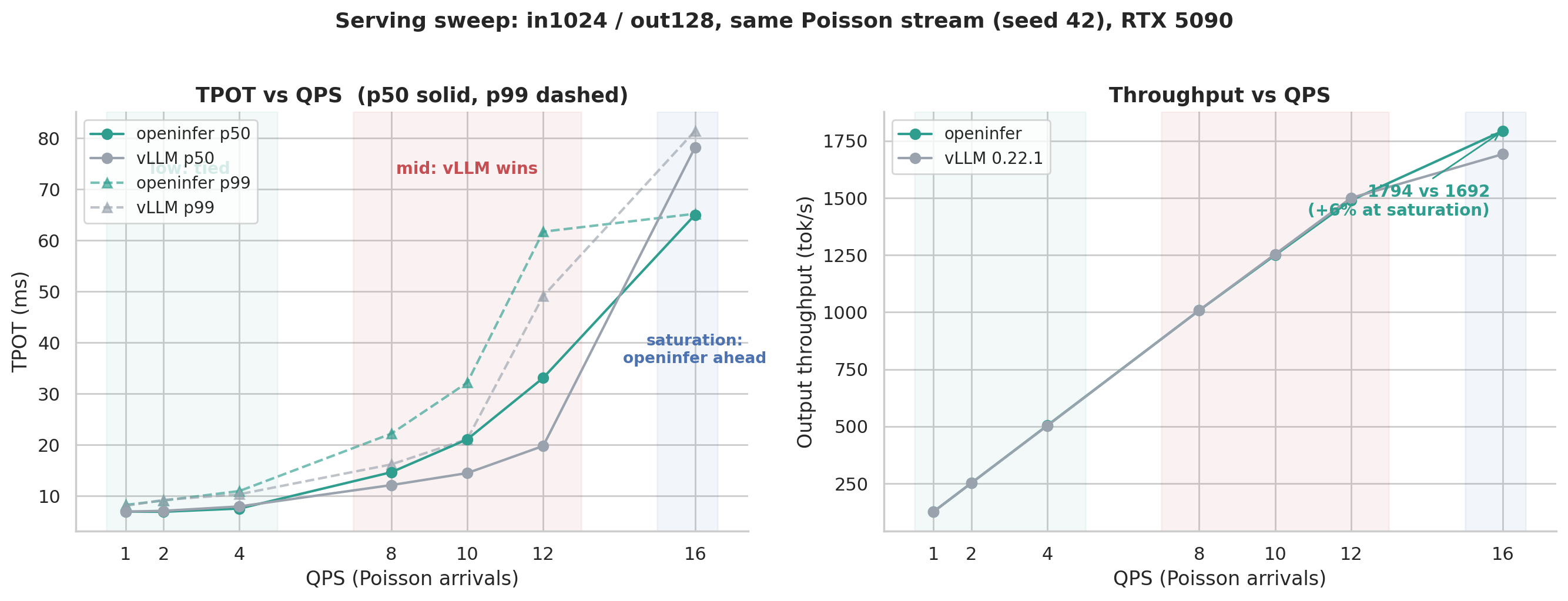
Low load, below QPS 4. TTFT and TPOT on both sides basically move together, with openinfer winning a little — TPOT p50 at QPS 2 and 4 is both lower than vLLM.
Medium load, QPS 8 to 12. Here it is indeed indeed a little lower than vLLM in performance, and TPOT is behind across the board.
Saturation point, QPS 16. Both sides are overloaded, TTFT goes to seconds, and openinfer is better instead — throughput 1794 vs 1692, 6% higher, and overloaded TPOT 65 vs 78, lower than vLLM.
However, no matter how you look at it, it is a kernel problem. To get better performance, tune the kernels and it is done.
KV Cache Benchmark: My Old Line of Work
Section titled “KV Cache Benchmark: My Old Line of Work”With coding agents exploding now, and with request hit ratios extremely high now (Kimi’s hit ratio on OpenRouter reached 98%), this means the system needs to process a large amount of high-hit-ratio cache. So we measured the performance when requests all hit GPU KV cache (same group of prompts; first send cold once to pour the prefix into the GPU cache, then send warm requests that hit cache), sweeping TTFT by input length:
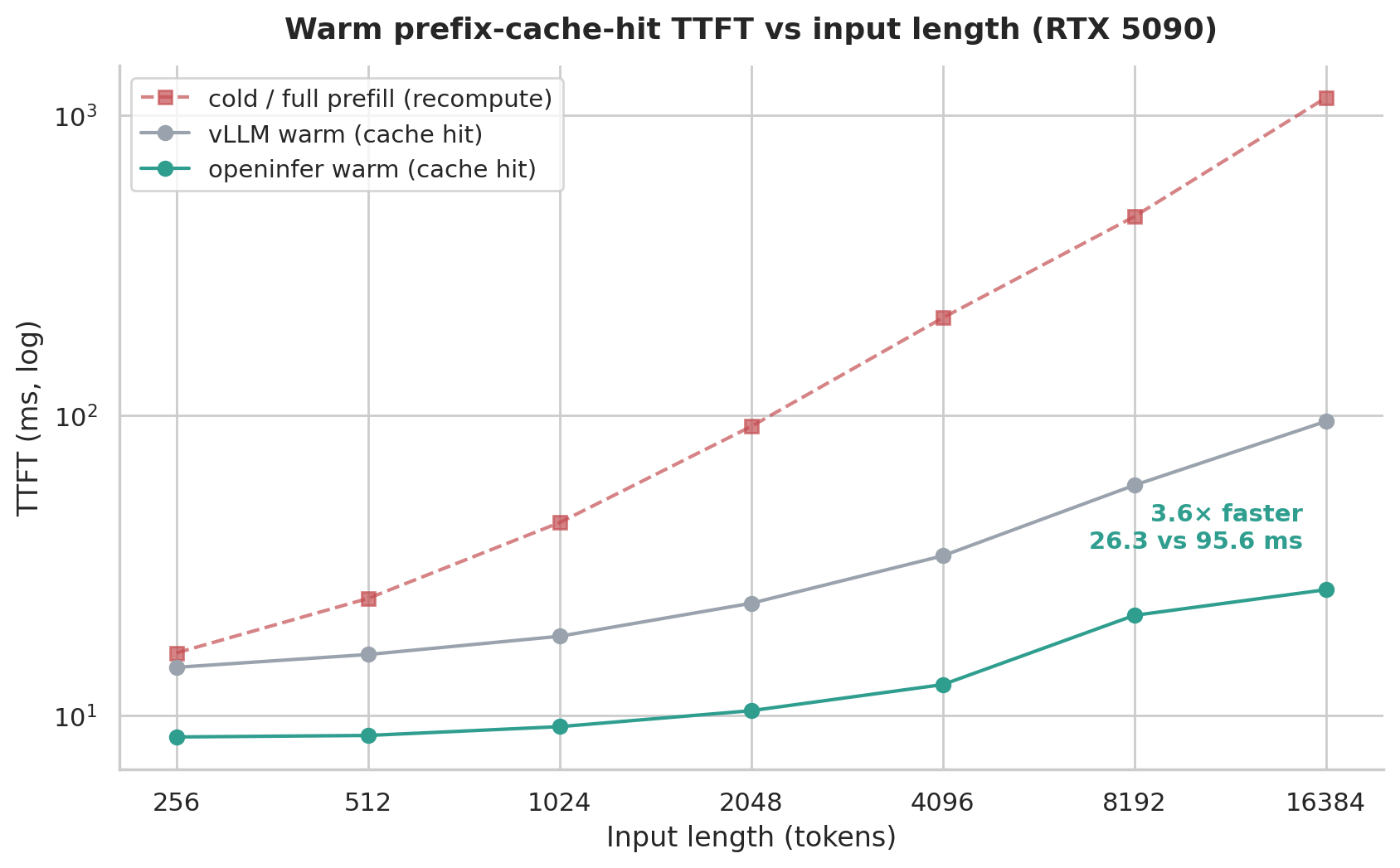
The largest single item in warm TTFT is CPU tokenization, that is, the tokenizer, taking about 30-40% of performance. After that are query and actual GPU execution.
Pegaflow: Also the Rust Project I Mainly Participate In
Section titled “Pegaflow: Also the Rust Project I Mainly Participate In”Pegaflow is the system I maintain most of the time. It is a KV offloading engine already running in production. In May, we also wrote a blog introducing it together with the vLLM team. It can be installed directly from PyPI, and experience, performance, correctness, and so on are all guaranteed (I checked, and the longest online running record is close to one month now; yes, residing on the server for one month, without any problem). Pegaflow does KV cache offloading in inference, tiered landing between HBM, DRAM, and SSD, and sharing across nodes with RDMA. Thanks to the fact that we have always connected to vLLM’s KV connector design, this lets our Rust service only care about KV cache, and integrate into OpenInfer with almost zero changes.
Performance, measured in pure L2 mode — turn off GPU prefix cache, force every hit to be fetched from CPU memory, and compare against full prefill cold send at the same length:
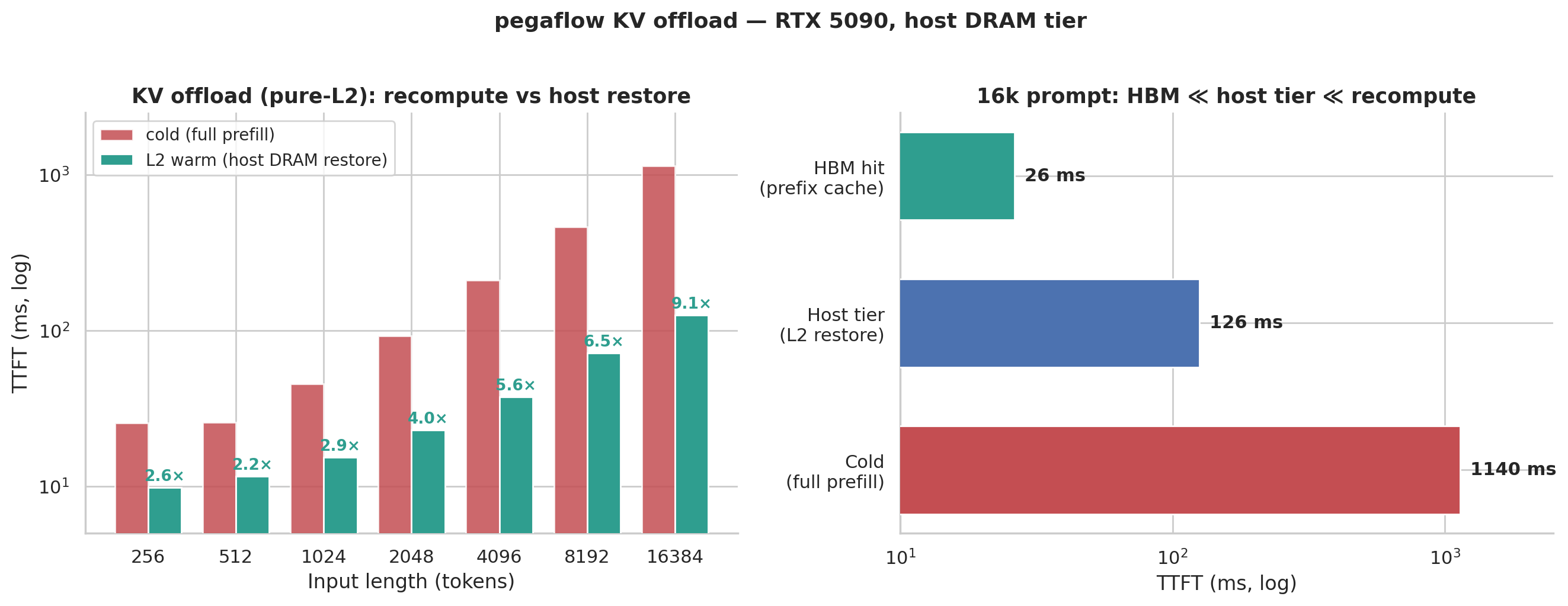
Because vLLM does not have officially recognized CPU memory, and when measuring other components I also do not know whose performance is better, I did not measure it.
Here Rust provides an interesting point: now KV Cache emphasizes async (all kinds of async, P/D async, I/O async, and so on). For example, when we do async SAVE, the task will hold the strong reference of the saved block (ImmutableBlock) until D2H actually lands before releasing it. Rust gives absolute correctness of lifetimes and data at the language level (other components use block id, and ZMQ, scheduler worker; if a problem happens, it is very hard to investigate).
Future: I Do Not Want to Make Another Large and All-In-One Inference Engine
Section titled “Future: I Do Not Want to Make Another Large and All-In-One Inference Engine”vLLM Rust, Dynamo, and Pegaflow actually point to a direction I become more certain about the more I think.
Although openinfer is currently one repository, I have not planned to make it into the kind of grand unified engine where “everything is owned by itself, everything grows together”. We have seen too many of that kind of engine: prefix cache, scheduler, kernel, and offload layer are tangled with each other; all kinds of features are mixed together; refactoring still has to keep compatibility, v1, v2, v3; at the same time, if you want to replace one part, you first need to read the whole engine once, and in the end nobody dares to change it. It is also hard for anyone to review PRs. If you fork and do it yourself, conflicts with upstream are troublesome, and at the same time, sometimes with some upstream features, after merging with the fork, who knows what problems there will be? It’s python.
So the next direction is the opposite: I plan to split openinfer into more independent sub-repos. Each one is a project with relatively stable and clear interfaces, can be quickly read and understood, and can be independently replaced. Pegaflow is already in this form — it can release independently and link independently. OpenInfer is only one of its many hosts.
The future I want is: these projects are on Rust’s package manager, crates.io, and you can pick a few to stitch together your own inference engine. Want to use xxx’s scheduler with pegaflow and then combine it with LORA? No problem. Tune kernels (mega-ize them), wrap them, and build your own inference service? Also possible. Experiments, LORA effects, RL-oriented scheduling algorithms, sparsification, speculative decoding experiments, and more aggressive scheduling algorithms (similar to nanoFlow), all are possible. Create a project, fill in the dependencies in Cargo.toml, and that is it.
For the openinfer repository itself, for 0.1.0, rather than saying it is a starting point, it is better to say it is the first sample stitched together from the previous ideas — these components can indeed be stitched together, providing production-grade performance and availability.
Thanks to all contributors:
xiaguan, CAICAIIs, FeathBow, Ma1oneZhang, NolanHo, mvanhorn, scatyf3, wjinxu, peter941221, Kozmosa, ywh555hhh, AgainstEntropy, Ke-Wng, advancebyanymeans, Mrtroll486, meddyck, jackyYang6.